Designing Trust: AI Governance in Agentic Automation
At a Glance
Role—I served as primary user researcher for two strategic AI Governance products (AI Guardrails + AI Evaluations) to ensure that governance features aligned with customer needs for safety, trust, and adoption
Methodology—I led multi-phase research spanning more than a year: development of a new user persona, concept validation with automation Center of Excellence professionals, foundational user surveys, in-depth interviews, and prototype walkthroughs
Impact—My research analysis and insights:
Produced and validated an all-new Governance, Risk and Compliance (GRC) Lead persona
Exposed comprehension barriers in AI Guardrail configuration
Validated strong demand for AI Evaluation tools, while clarifying the need for education around runtime monitoring
Highlighted trust signals—pass/fail indicators, evaluation summaries, and audit logs—that became roadmap priorities
Research Artifacts—Research plans, GRC persona, insights shareouts
Overview
When Automation Anywhere introduced AI Skills as part of its AI Agent Studio offering, it marked a paradigm shift from traditional rules-based automation toward generative AI-powered automation. By building an AI Skill (or LLM prompt template, intended for reuse across automations) into a process flow, customers now had powerful new ways to bring the power of models to workflow automation.
These AI capabilities also introduced unprecedented challenges around safety, reliability, and trust.
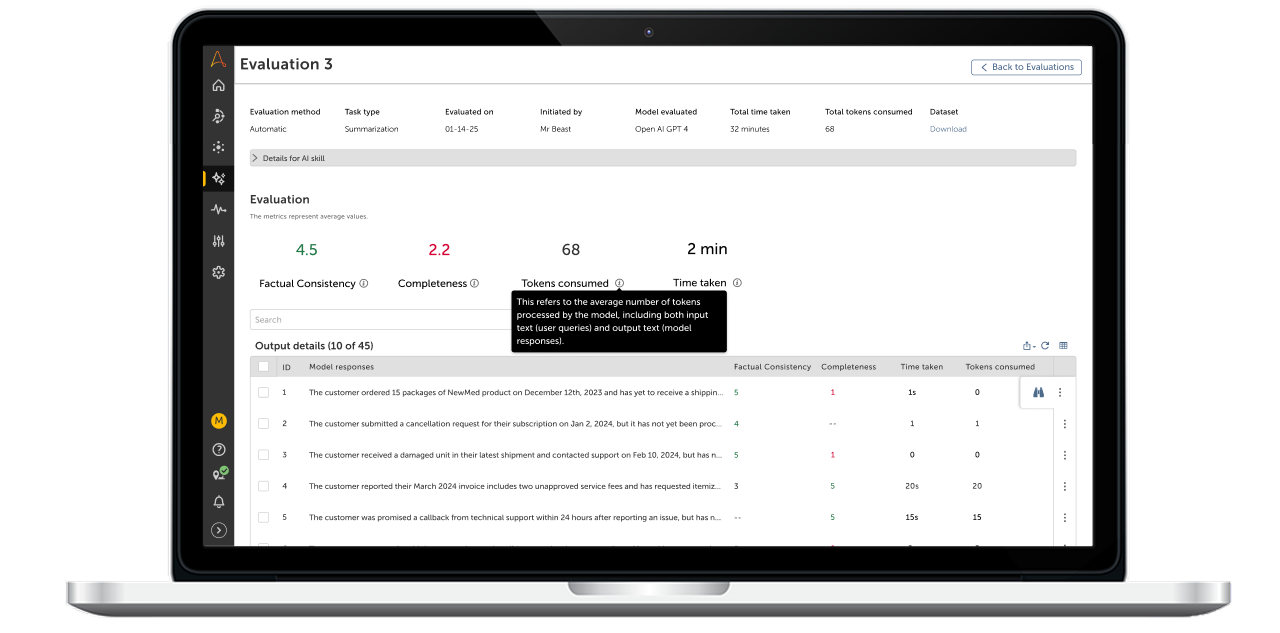
AI Governance features enable enterprises with tools to keep the use of AI in automation safe and reliable — shown here in an AI Evaluation results screen that measures performance before deployment.
Problem Space

AI GUARDRAILS
Is AI safe to use?

AI EVALUATIONS
Is AI reliable?
AI Evaluations was designed to enable customers to test the accuracy and performance of AI Skills prior to deployment. Importantly, the AI Evaluation feature was conceived not just for AI Skills but with an eye toward the next horizon: AI Agents, which will semi-autonomously orchestrate multi-step processes using AI Skills and other connected tools to achieve a predefined goal.
Automation Anywhere led the market by rolling out AI Guardrails functionality to protect both users and data. AI Guardrails filter toxic or unsafe content and mask sensitive information — such as PII or PCI — before it reaches the model or is exposed to the end user. By giving customers clear, enforceable safeguards, AI Guardrails provided the foundation of trust for using AI Skills in production automations.
Research Goals
My role was to craft and lead the research program that directly tackled these two complementary governance challenges.
AI EVALUATIONS
Timing of evaluation
🔎 Do users expect to test automations only before deployment, or also continuously at runtime?
👉 If expectations don’t align with product design, evaluations won’t fit workflows and enterprises may miss post-deployment failures.
Metrics that matter
🔎 What signals (e.g., pass/fail, summaries, audit logs) build confidence in results?
👉 Without meaningful signals, users may avoid reusing shared assets—or worse, deploy unreliable ones at scale.
Role differences
🔎 How do expectations vary across developers, admins, and governance leaders?
👉 If role-specific needs aren’t addressed, governance tools risk favoring one group at the expense of others, stalling enterprise adoption.
AI GUARDRAILS
Clarity of purpose
🔎 Do users understand what guardrails are for, and what characterizes the initial conceptual model?
👉 Without clarity and framing, safeguards could be underutilized or mistakenly applied, undermining adoption and trust
Flexibility vs. simplicity
🔎 How much guidance and control do users want in configuring safeguards?
👉 Too much complexity overwhelms users; too little flexibility makes the product unusable for enterprise governance
Trust signals
🔎 What reassures users that guardrails are activated and effective (e.g., confirmation of masking, visible filtering)?
👉 Without visible feedback, guardrails risk being seen as a “black box,” reducing confidence in adoption.
Methodology
Spanning more than a year, I led research combining qualitative depth with large-scale validation. Each stage reflected the maturity of the product roadmap and focused on bringing forward the perspectives of automation developers, admins, and governance leaders. Across all phases, I documented research artifacts—including personas, interview findings, survey reports, prototype studies, and stakeholder shareouts—to ensure insights could directly inform design priorities and governance strategy.
-
Outside of our validated set of automation user personas, I identified a missing voice: Governance, Risk, and Compliance (GRC) leaders. This audience approaches AI adoption with priorities around regulatory alignment, audit readiness, and enterprise risk management. I conducted research to define and formalize a new persona, the GRC Lead, to integrate seamlessly into our product framework so governance concerns could be explicitly represented in design decisions.
-
I began with semi-structured interviews and prototype walkthroughs to explore how automation developers interpreted AI Guardrails, what they expected from these safeguards, and how they gauged trust.
These exploratory sessions exposed early signs of comprehension and configuration challenges. To validate these risks at scale, I partnered with Helio to run a proof-of-concept test with 650+ IT professionals and decision makers. This provided benchmark data on comprehension, click success, and sentiment, and served as evidence for adopting a broader research platform.
-
For AI Evaluations, I led a mixed-method study that combined a Qualtrics survey with targeted interviews across industries like healthcare and financial services.
The survey quantified current evaluation practices and adoption barriers, while the interviews revealed workflow details and compliance expectations. Later, I ran prototype walkthroughs with developers, admins, and GRC Leads to test navigation flows, reporting formats, and role-specific usability. These sessions clarified how AI Evaluations could support both development-time testing and runtime monitoring.
Insights and Strategic Impacts
AI Guardrails – Is AI Safe to Use?
Insights: Early designs left users uncertain whether guardrails were working. Rule configuration was perceived as overly complex, and defaults caused more confusion than clarity. The Helio study quantified these concerns at scale: comprehension of the masking flow was well below benchmark, first-click success lagged, and sentiment clustered around “confusing” and “complicated.”
Strategic Impact: My research directly shaped the product direction: guardrails moved toward template-based defaults rather than freeform setup, terminology was simplified to reduce friction, and confirmation signals (logs, previews) were added to build trust. Beyond product changes, the Helio proof-of-concept provided leadership with evidence of the value of scaled testing, helping establish a stronger research practice inside the organization.
AI Evaluations – Does AI Work Reliably and as Expected?
Insights: Enterprise customers recognized the importance of testing AI, but their practices were inconsistent and often manual. Surveys and interviews revealed strong demand for automated comparisons and flagged compliance risks around dataset use. Prototype walkthroughs confirmed that while results were easy to follow, confidence remained moderate, and expectations diverged by role: developers preferred evaluation within the editor, while admins and compliance leaders looked for global oversight.
Strategic Impact: These findings reframed Evaluations from a developer-only tool into a cross-role governance capability. My research drove design priorities for dual entry points (editor + global navigation), plain-language metrics and pass/fail thresholds to improve confidence, and exportable reports to meet compliance needs. In doing so, it positioned Evaluations not just as a testing feature but as a cornerstone of enterprise adoption strategy.